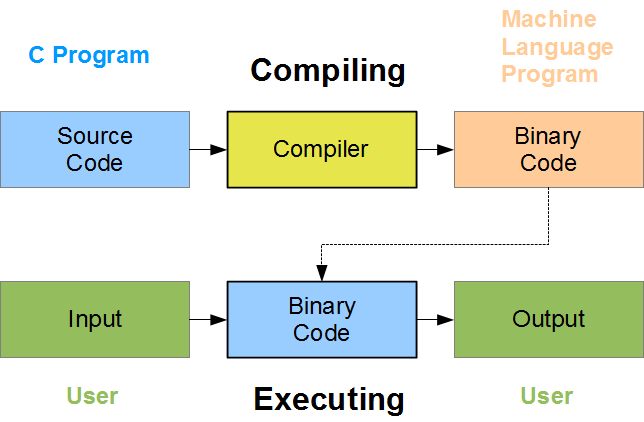
stanford 的 compiler 暂时还没有开课,但是我已经在看作业说明了,发现第一个作业的说明怎么这么难懂,这要尼玛说什么啊。
所以就把作业说明先翻译出来,自己做个笔记,以后开课的时候可以看。
作业说明
下面是用flex做词法分析器要求的翻译,其他的资源如cool手册和flex的手册课程上都有给链接。
3.文件和目录
要开始的话,在你想要做作业的地方创建一个新的目录,执行下面的指令在那个新目录。
make -f /usr/class/cs143/assignments/PA2/Makefile
这个命令将产生一堆文件,下面对三个文件进行说明:
cool.flex
这个文件包含了一个Cool的词法分析器骨架。里面有注释会指导你该怎么写代码,但是这些注释不是一个完整的说明。这个作业的一部分目的是为了让你清楚你有一个正确的词法分析器。除了这个章节的指引,你也可以自己加一些特别的东西进去。你可以在这个骨架上构造一个词法扫描器,但不是必要的。你应该去阅读好flex的手册去弄明白这段描述究竟让你做什么。其他任何的你想要在这个骨架上加的常规的东西都应该直接加到这个骨架上的合适的位置。(去研究那些注释吧,少年。)
test.cl
这个文件包含了一些正常的输入可以被词法分析器扫描。它不会包含了Cool语言的所有语法特性,但是不影响它是一个有趣的测试文件。你也可以自由地去修改这个文件被你的词法分析器扫描。
4 词法扫描结果
在这个课程中,你需要写Flex的规则去匹配正确的正则表达式,认证Cool正确的taken,产生正确的动作,纪录词法的值,或者抛出错误当错误条件触发时。有关正确token资料在Cool手册的第十章第一节上。在你做这个作业之前,确保你认真阅读了Cool手册的第十章第一节,然后学习不同的token是怎么在cool-parse.h文件上定义的(这个文件在cool编译器中有)。你应该实现Flex的规则为每个在cool-parse.h上定义的正确的token,去匹配对应的正则表达式,为每个token执行正确的动作。例如:假如你匹配了一个BOOL_CONST的token,你的词法分析器必须记录这个bool的值是真还是假;相似的,假如你匹配了一个TYPEID的token,你应该记录这个type的的名字。注意,不是每个token都需要记录额外的信息;例如,只有返回的token类型符合某些token类型才需要记录额外信息,例如:keywords。
你的词法扫描器健壮性一定要强,应该可以在任何可以想象到的输入都正常工作。例如,你必须要处理错误,当关键词EOF出现在字符串或者注释中间的时候,还有就是字符串过长的情况也要考虑。这都是一些你应该处理的常见错误,其余的部分自己看手册啦。
假如一个错误出现,你必须优雅地引起错误并显示。核心异常或者不可捕捉的异常是不可以接受的。
4.1 错误处理
所有错误信息都应该传递语法分析器。词法分析器不应该输出任何东西。错误应该通过返回特殊的错误信息ERROR与语法分析器进行交流(注意,你应该忽视名为error的token,这个是在作业3中的语法分析器中用的)。还有几个需要注意的地方需要词法分析器错误抛出:
当一个不合法的字符(一个不匹配任何token的字符)出现的时候,那个包含这个字符的字符串应该返回为一个错误的字符串。继续为下一个token进行解释。
假如一个字符串含有一个unescaped的新行,报告这个错误为‘‘Unterminated string constant’’,然后继续解析下一行,我们假设程序员忘记了写引号的下一半。
假如一个字符串太长,报告这个错误为‘‘String constant too long’’为这个字符串类型为ERROR。假如这个字符串含有不合法的字符(例如:null字符),报告这个错误为 ‘‘String contains null character’’。在任何错误情况下,词法解析器都应该在这个字符串的结尾为下一个字符解析。这个结尾应该是下面这几种情况:
- 这个错误出现之后,假如一个unescaped的新行出现在这个下一行的开始。
- 在”之后。
假如一个注释里面有EOF关键词,报告这个错误‘‘EOF in comment’’。不要尝试去解析注释里面的内容。类似的,假如一个字符串里面有EOF关键词,报告这个错误‘‘EOF in string constant’’。
假如有”*)” 在一个注释之外,报告这个错误‘‘Unmatched *)’’,而不要分析它为 * 和 )。
回想起这次课,这阶段的编译器只是捕捉非常有限的错误。不要尝试去检查不是在词法解析器的错误。例如,不应该检查一个在用变量之前,变量是否声明了。确认你充分了解什么错误处理词法分析器应该做,在你没有了解之前不要开始。
4.2 字符串表
程序会对一个token分析多次。例如,一个定义标示一般都会在程序中用到很多次。为了节省空间和时间,一个正常编译器的实现方法是保存词法在一个字符串表上。我们提供一个字符串表的C++接口。
有一个问题,就是怎么为基础的类(Object, Int, Bool, String),SELF_TYPE和self,去处理特殊的定义标示。在语法分析器部分之前,这个问题不会真正出现。词法分析器应该处理这些特殊标示符像其他定义标示一样。
4.3 字符串
词法分析器应该对一个字符串的中逃离的字符进行转义,变成一个正确的字符串。例如,假如这个字符串为”ab\ncd”,词法分析器应该返回 STR_CONST,值为ab\ncd,其中\n为单独的字符。根据Cool手册第15页的描述,你应该为包含了null字符的字符串返回一个错误信息。像\0这样的转义字符应该转化为0。
4.4 其他需要注意的地方
词法分析器因该保留变量curr_lineno,指出现在分析的词是在源文件中的第几行。这个功能会帮助语法分析器打印出有用的错误信息。
你应该忽视token LET_STMT。这个会在作业3中的使用。最后,注意假如词法分析器不完整的话,flex生成的C语言文件将不能正常运行,保证每一部分都正确。
5 特别注意
- 每次token解析完,都需要从输入中对下一个token进行处理。这个值的返回的函数为cool_yylex,是一个完整的代码,代表了语法的类型(例如:整型语法,分号,关键字等等)。所有token的定义代码在cool-parse.h上。第二部分,token的值或词法单位,放在了一个全局变量cool_yylval中,它的类型是YYSTYPE。 YYSTYPE类型同样被定义在cool-parse.h中。单个字符符号的token(例如:;和,)代表着对应的ASCII值。所有单个字符token都被列在了Cool手册的语法部分上。
- 对于类,对象,整型,字符串的标示符,语意值应该为一个符号保存在cool_yyval.symbol文件中。对于布尔型变量,语意值应该保存在cool_yylval.boolean文件中。除了错误之外,其他词法解析的token都不需要携带其他游泳的信息。
- 我们提供了一个字符串表的实现,细节讨论在A Tour of the Cool Support Code这个页面上。在这个时间,你只需要去了解字符串表的输入类型是Symbol。
- 当一个词法错误发生的时候,cool_yylex应该返回ERROR的token。语意值为该字符串代码的错误信息,应该存储cool_yylval.error_msg文件(这应该是一个原始的字符串,而不是symbol)。
